Full bandwidth player. Sequence fraud discussion starts at 40 minutes. Poornima Wagh starts at 1:37 and Tantra Studio starts at about 2:43. An article describing the virus fraud issue is below the three-card Monte video frame; and there is additional information in the comments.
Lower bandwidth player
On tonight’s edition of Planet Waves FM, we will go deep into the 12th house nature of virology. I’ll mix that up with some nuclear war black comedy, a bit of jazzy music, and thoughts on record producer Daniel Lanois (who makes a cameo). The program usually posts before its scheduled 10 pm EDT time.
Note: See article below the video frame.
Tonight I will be at my very best to make plain what is going on behind the scientific claims you’ve heard so much about everywhere else. As you may know, I’ve been working for more than two years on a daily chronology related to the PCR test and in silico genetic alignment. Over the past two weeks I’ve had several breakthroughs putting together the pieces of this sprawling mystery.
In sum: In early January 2020, there were two primary sequences that were considered “the real SARS-CoV-2.” The very first was called MN908947 (by the Fan Wu team) and the other was 402123 (by Li-Li Ren, associated with the Little Dog team). I have learned that on Jan. 12, 2020 (the day of the Saturn-Pluto conjunction), one sequence was substituted for the other, and the authors of the “rewritten” sequence were concealed from public view.
I will tell the story of this virus shell game, and offer my thoughts about the implications.
Mark Bailey and Tom Cowan, audio file below.
The Virus Challenge and Dr. Poornima Wagh
Here is audio of the virus challenge introduction, presented by Drs. Bailey and Cowan. It’s not that exciting — I will explain what they are doing at the top of the second segment of the program.
Finally, I will have an interview with virologist Poornima Wagh conducted by Regis Tremblay, which goes into how a group of virologists in California were given 1,500 “PCR-positive”samples by the state, but could not find anything other than “random cellular debris.”
We Can Only Do This With Your Help
Planet Waves FM and Chiron Return are a separate budget and content stream from Planet Waves, the astrology website. We offer a calm and reflective environment rather than the usual cortisol-and-agony-infused programming that triggers people and thereby provokes action. And we offer the best news astrology anywhere.
If you value and appreciate my journalism, thank you for doing your small part. In our current environment of censorship and cancel culture, we have survived only due to the conscientious support of people such as yourself, who simply care enough to take action. Thank you. And thank you for spreading the word.
Faithfully,
PS — If you are the steward of a charitable family trust and want to offer resources to a nonprofit doing excellent journalistic work, please contact me at efc@chironreturn.org, or call me at (845) 481-5616. We have plans, and you may be the one to help make them happen. Thank you.
When the “covid test” searches for a virus from a human sample, what is it looking for? We are told “SARS-CoV-2” or the “covid virus,” but those are not technical scientific references. They are more like nicknames.
When China famously publishes the “suspect virus” c. Jan. 11, 2020, they are referring to something called MN908947, which is soon credited to a team led by Fan Wu, et al. That becomes the “mother of all SARS-CoV-2 genomes.” It is the one released to the World Health Organization and all others as THE virus. It is also the one cited by the US CDC. It was “discovered” by a team with public health associations, including the Shanghai Public Health Center and the University of Sydney, Australia.
Simultaneously, the Little Dog team at Vision Medicals, and others in the private sector, were part of a consortium cooking up another sequence using Johns Hopkins software called Kraken2, which is clade exclusion and modeling software.
They get the thing they really want, and also it’s sampled from a guy who will become the first person said to have ‘died of covid’ — 61-year-old patient with numerous other diseases for whom David Rasnick said they were utterly determined to find a viral cause.
They release the sequence, but do not publish a scientific paper for 402123, because if they do, all the names and corporate affiliations associated with it will come up.
So they aim the MN908947 series to match 402123, and that is the reason for the previously mysterious revisions, MN.1, MN.2, MN.3. The second in the series is published Jan. 14, 2020, three days after the patient from whom the crude sample for 402123 was taken dies of multiple illnesses.
They apparently get what they need from the in silico sequence MN908947.2 because that is currently cited by CDC as the source of its PCR primers; and was also cited in the Corman-Drosten paper, which is WHO’s official assay. Neither CDC nor WHO mention 402123 as the source of their primers; both however mention MN908947.2 as the source of theirs.
Technicians and their bosses matched the sequence they wanted to prime the PCR with, while concealing the names and institutions that come up with the desired sequence (402123), and they dropped that sequence into the MN908947 series, which brings up Fan Wu as its author — not Lili Ren or Little Dog at Vision Medicals, nor the rest of them with their corporate ties.
In their paper, Corman and Drosten show that they align their PCR primers to match both MN908947.2 and 402123, which is presented anonymously. It therefore seems like two different sequences by two different teams have come up with the same thing. But really, 402123 has been merged into the MN908947 pedigree.
402123 is the desired sequence because it was designed on Kraken2, which matches for genus, not for specific “virus,” so it will result in much broader “search returns” when the public is subjected to it.
Instead of finding a sequence connected to one specific “virus,” as is the superpower of the PCR when used properly, it will pick up a diverse variety of “viral” cellular debris, meaning that it will be cross-reactive, resulting in “false positives.”
But there are no true positives as there is nothing to affirmatively match against as there is no actual master sequence of wild, live virus. The only sequences are metagenomic transcripts, which are theoretical sequences, not real ones; they have never been shown to even match live virus.
Finally, the Lili Ren team’s paper (the Little Dog team) claiming credit for 402123 appears in Chinese Medical Journal in May 2020 when and where nobody is looking. Nobody knows or cares or even thinks to match that back to MN908947, or understands it was effectively switched out within that series.
+++++++ Or said another way +++++++
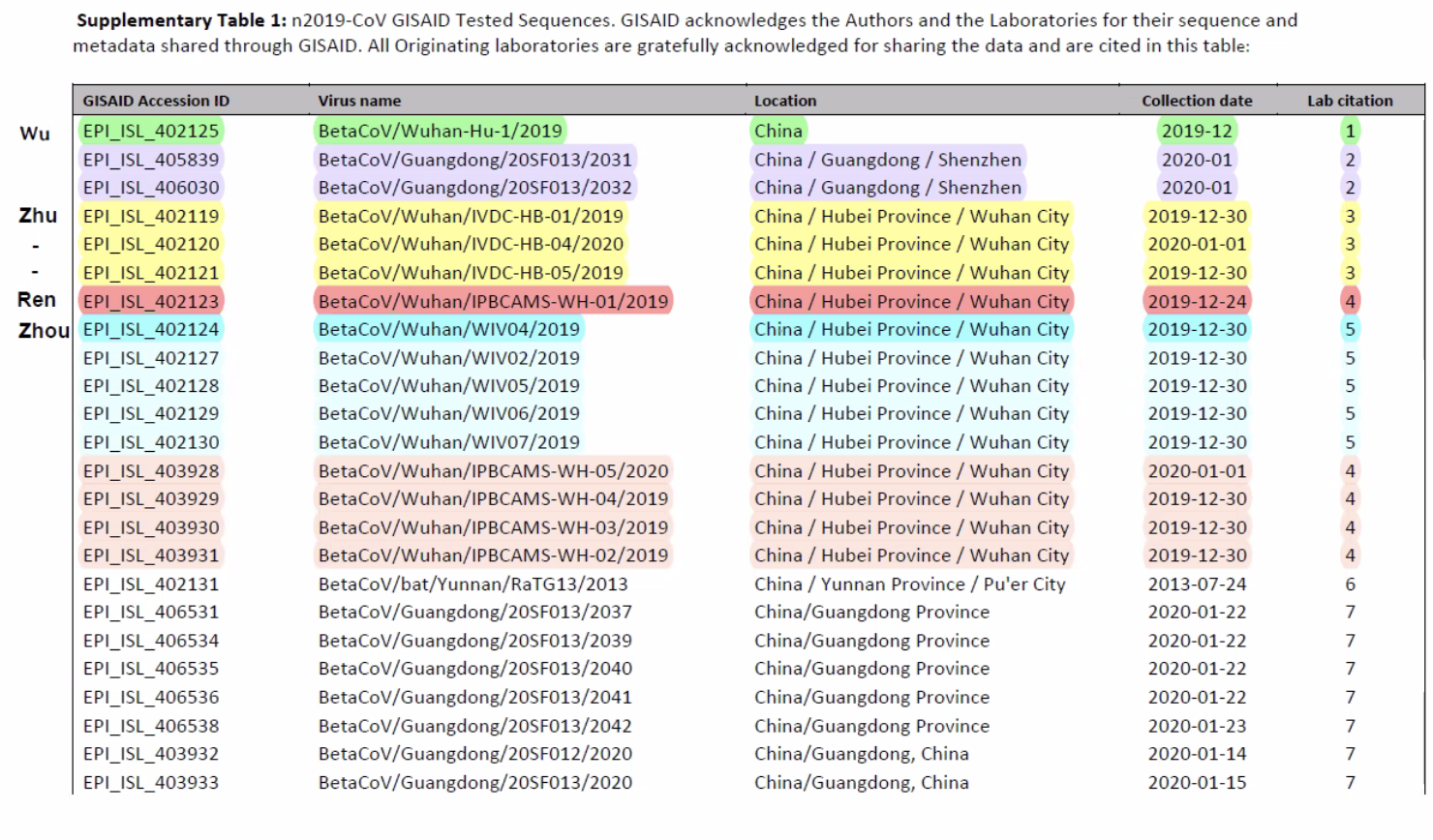
Chart showing the four major teams that worked on virus creation in January 2020.
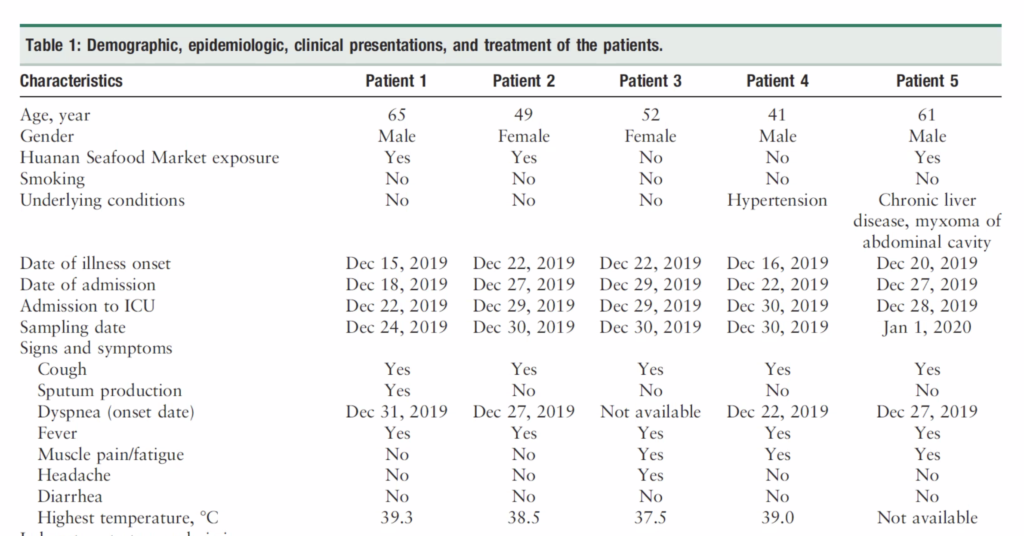
The sequence in red is by the Lili Ren team, which came up with 402123; this is Vision Medicals (Little Dog team), and they are using Kraken2, which is a Johns Hopkins application (clade exclusion) that is used only to sort out the genus, not find the specific virus. Their sample is Patient 5 in the Lili Ren paper (see table below). That is the guy with 10 diseases who dies 1/11/20 — “the first covid death.”
Internally, this becomes the “model virus.” But a very different sequence had already been published as MN908947 (by the Fan Wu team in green)
This sequence goes through three versions to version .3, it rapidly “catches up” and aligns with 402123 and is finally republished as 402125. Version MN908947.1 is nothing like version MN908947.2 or .3. It is edited to match the “first claimed whole sequence” (402123) published in the Lili Ren paper (see patient table below). So in effect. 402123 is renamed and that sequence — MN908947.2 — is used for the primer design by CDC and Corman-Drosten (WHO).
Patients referred to in the Lili Ren paper by the Little Dog team, including Vision Medicals.
4 Comments
Regarding recent developments:
What we are tracking is what sequences ended up as primer sources for Corman-Drosten (WHO) and CDC assays. There were about 27 published genomes by January 25, 2020!
In fact all that is officially listed by C-D and CDC as a source of primers is GenBank MN908947.2, which genetically aligns with 402123, and is also repackaged and resubmitted to GISAID as 402125.
So simply put:
On Jan. 5, 2020, one team (Fan Wu) posts MN908947 and WHO says eureka! We found it. This is posted to GenBank, making it the first published sequence.
That is upgraded in GenBank to MN908947.1 on Jan. 11, the same day that 402123 is posted to GISAID, a different system. This replaces MN908947.
The next day, Jan. 12, 2020, MN908947.2 is posted to GenBank, replacing MN908947.1 and it genetically aligns with 402123. (They are described as “complimentary sequences.”)
However, only MN908947.2 is listed as the source of primers by CDC or C-D. 402123 does not get attributed as a primer source.
The Fan Wu paper comes out Feb. 3, 2020, documenting who worked on MN908947 but not accounting the revisions. The Fan Wu paper leaves out the upgrades .1, .2, .3 entirely! They are not there! Nor is 402123.
402123 is not listed anywhere as the source of primers. It’s merely something that “aligns with” MN908947.2.
We don’t find out who created 402123 until May 5, 2020, when the Li-Li Ren paper is published, and we discover that it’s a corporate project involving:
— Johns Hopkins, creator of Kraken2 clade exclusion and modeling software used to create 402123
— Peking Union Medical College
— Vision Medicals Co
— Christophe Merieux Laboratory
— Institute of Pathogen Biology (IPB), Chinese Academy of Medical Sciences & Peking Union Medical College
EVEN SIMPLER
— The Fan Wu paper of Feb 5 2020 claims credit for GenBank MN908947 but omits the revisions. It merely accounts for the first iteration even though .3 was published Jan. 17, 2020, long before the Fan Wu paper is final.
— Nobody accounts for how GenBank MN908947 rapidly evolves into something that aligns with 402123, or evolves at all. It is nowhere in the Fan Wu paper, where it belongs.
— The delay of the Li-Li Ren paper until May 5, 2020 conceals the authorship of GISAID 402123.
— Nobody accounts for how GISAID 402125 is exactly the same as GenBank MN908947.2, though it’s not remarkable in itself that the same sequence is filed on two systems. It is the timing that is interesting.
Both appear on Jan. 12, 2020, right after GISAID 402123 is published.
Under this theory, the following should all align or match exactly
402123
402125
MN908947.2
There is a tactic used in Congress and state legislatures, called “gut and replace,” used to push through bills which are facing opposition. A bill already passed in the particular chamber (house, senate) which is pretty meaningless is amended, its contents either gutted or allowed to stand given they are not important anyway, and the contents of a bill which is stalled in committee are added to it. Thus, the bill has made its way around the committee process. What’s described here is a biomedical equivalent This is damn shattering!!




Regarding recent developments:
What we are tracking is what sequences ended up as primer sources for Corman-Drosten (WHO) and CDC assays. There were about 27 published genomes by January 25, 2020!
In fact all that is officially listed by C-D and CDC as a source of primers is GenBank MN908947.2, which genetically aligns with 402123, and is also repackaged and resubmitted to GISAID as 402125.
So simply put:
On Jan. 5, 2020, one team (Fan Wu) posts MN908947 and WHO says eureka! We found it. This is posted to GenBank, making it the first published sequence.
That is upgraded in GenBank to MN908947.1 on Jan. 11, the same day that 402123 is posted to GISAID, a different system. This replaces MN908947.
The next day, Jan. 12, 2020, MN908947.2 is posted to GenBank, replacing MN908947.1 and it genetically aligns with 402123. (They are described as “complimentary sequences.”)
However, only MN908947.2 is listed as the source of primers by CDC or C-D. 402123 does not get attributed as a primer source.
The Fan Wu paper comes out Feb. 3, 2020, documenting who worked on MN908947 but not accounting the revisions. The Fan Wu paper leaves out the upgrades .1, .2, .3 entirely! They are not there! Nor is 402123.
402123 is not listed anywhere as the source of primers. It’s merely something that “aligns with” MN908947.2.
We don’t find out who created 402123 until May 5, 2020, when the Li-Li Ren paper is published, and we discover that it’s a corporate project involving:
— Johns Hopkins, creator of Kraken2 clade exclusion and modeling software used to create 402123
— Peking Union Medical College
— Vision Medicals Co
— Christophe Merieux Laboratory
— Institute of Pathogen Biology (IPB), Chinese Academy of Medical Sciences & Peking Union Medical College
EVEN SIMPLER
— The Fan Wu paper of Feb 5 2020 claims credit for GenBank MN908947 but omits the revisions. It merely accounts for the first iteration even though .3 was published Jan. 17, 2020, long before the Fan Wu paper is final.
— Nobody accounts for how GenBank MN908947 rapidly evolves into something that aligns with 402123, or evolves at all. It is nowhere in the Fan Wu paper, where it belongs.
— The delay of the Li-Li Ren paper until May 5, 2020 conceals the authorship of GISAID 402123.
— Nobody accounts for how GISAID 402125 is exactly the same as GenBank MN908947.2, though it’s not remarkable in itself that the same sequence is filed on two systems. It is the timing that is interesting.
Both appear on Jan. 12, 2020, right after GISAID 402123 is published.
Under this theory, the following should all align or match exactly
402123
402125
MN908947.2
There is a tactic used in Congress and state legislatures, called “gut and replace,” used to push through bills which are facing opposition. A bill already passed in the particular chamber (house, senate) which is pretty meaningless is amended, its contents either gutted or allowed to stand given they are not important anyway, and the contents of a bill which is stalled in committee are added to it. Thus, the bill has made its way around the committee process. What’s described here is a biomedical equivalent This is damn shattering!!
I knew it reminded me of something.